

ကြီးမားသောဘာသာစကားပုံစံများကား အဘယ်နည်း။
ကြီးမားသော ဘာသာစကားပုံစံများ (LLM) များသည် လူသားနှင့်တူသော စာသားများကို လုပ်ဆောင်ရန်၊ နားလည်ရန်နှင့် ထုတ်လုပ်ရန် ဒီဇိုင်းထုတ်ထားသော အဆင့်မြင့် ဥာဏ်ရည်တု (AI) စနစ်များဖြစ်သည်။ ၎င်းတို့သည် ဝဘ်ဆိုက်များ၊ စာအုပ်များနှင့် ဆောင်းပါးများကဲ့သို့ အမျိုးမျိုးသော အရင်းအမြစ်များမှ စကားလုံး ဘီလီယံပေါင်းများစွာ ပါဝင်လေ့ရှိပြီး နက်နဲသော သင်ယူမှုနည်းစနစ်များကို အခြေခံကာ ကြီးမားသောဒေတာအတွဲများပေါ်တွင် လေ့ကျင့်သင်ကြားထားသည်။ ဤကျယ်ပြောလှသောလေ့ကျင့်မှုသည် LLM များသည် ဘာသာစကား၊ သဒ္ဒါ၊ အကြောင်းအရာနှင့် အထွေထွေဗဟုသုတ၏ အချို့သောကဏ္ဍများကိုပင် နားလည်သဘောပေါက်နိုင်စေပါသည်။
OpenAI ၏ GPT-3 ကဲ့သို့ လူကြိုက်များသော LLM အချို့သည် Transformer ဟုခေါ်သော အာရုံကြောကွန်ရက် အမျိုးအစားကို အသုံးပြုကြပြီး ရှုပ်ထွေးသော ဘာသာစကားတာဝန်များကို ထူးထူးခြားခြား ကျွမ်းကျင်မှုဖြင့် ကိုင်တွယ်နိုင်စေပါသည်။ ဤမော်ဒယ်များသည် အလုပ်များစွာကို လုပ်ဆောင်နိုင်သည် ၊
- မေးခွန်းများကိုဖြေဆိုခြင်း။
- စာသားအကျဉ်းချုပ်
- ဘာသာပြန်ခြင်း
- အကြောင်းအရာကို ဖန်တီးခြင်း။
- အသုံးပြုသူများနှင့် အပြန်အလှန် ထိတွေ့ပြောဆိုမှုများတွင်ပင် ပါဝင်နေပါသည်။
LLM များသည် ဆက်လက်တိုးတက်ပြောင်းလဲလာသည်နှင့်အမျှ ၎င်းတို့သည် ဖောက်သည်ဝန်ဆောင်မှုနှင့် အကြောင်းအရာဖန်တီးမှုမှ ပညာရေးနှင့် သုတေသနအထိ စက်မှုလုပ်ငန်းခွင်များတွင် အမျိုးမျိုးသော အပလီကေးရှင်းများကို မြှင့်တင်ရန်နှင့် အလိုအလျောက်လုပ်ဆောင်ရန် အလားအလာကောင်းများကို ကိုင်စွဲထားသည်။ သို့သော်လည်း ၎င်းတို့သည် နည်းပညာတိုးတက်လာသည်နှင့်အမျှ ကိုင်တွယ်ဖြေရှင်းရန် လိုအပ်သည့် ဘက်လိုက်သောအပြုအမူ သို့မဟုတ် အလွဲသုံးစားလုပ်မှုကဲ့သို့သော ကျင့်ဝတ်နှင့် လူ့အဖွဲ့အစည်းဆိုင်ရာ စိုးရိမ်မှုများကိုလည်း မြှင့်တင်ပေးပါသည်။

ကြီးမားသော ဘာသာစကားမော်ဒယ်များ၏ လူကြိုက်များသော ဥပမာများ
ဤသည်မှာ မတူညီသောစက်မှုလုပ်ငန်းဒေါင်လိုက်များတွင် တွင်ကျယ်စွာအသုံးပြုသော LLM များ၏ ထင်ရှားသောဥပမာအချို့ဖြစ်သည်။
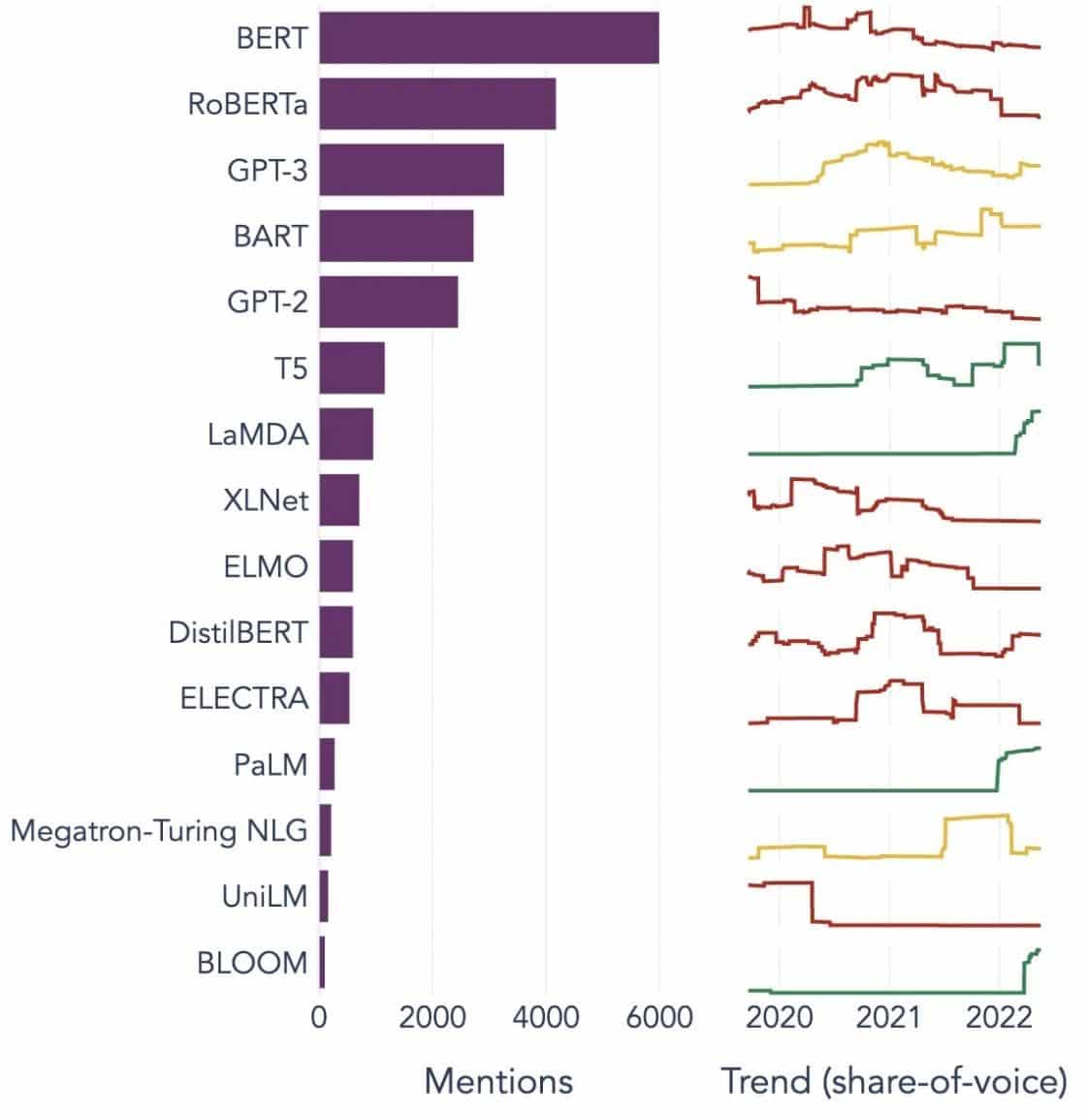
Image ကိုရင်းမြစ်: ဒေတာသိပ္ပံဆီသို့
LLM မော်ဒယ်များကို မည်သို့ လေ့ကျင့်သင်ကြားပေးသနည်း။
ကြီးမားသောဘာသာစကားပုံစံများ (LLMs) လေ့ကျင့်ခြင်းသည် အလွန်အရေးကြီးသော အဆင့်များစွာပါဝင်သည့် လုပ်ဆောင်ချက်တစ်ခုဖြစ်သည်။ ဤသည်မှာ လုပ်ငန်းစဉ်၏ ရိုးရှင်းပြီး အဆင့်ဆင့် ကောက်ချက်ချသည်-
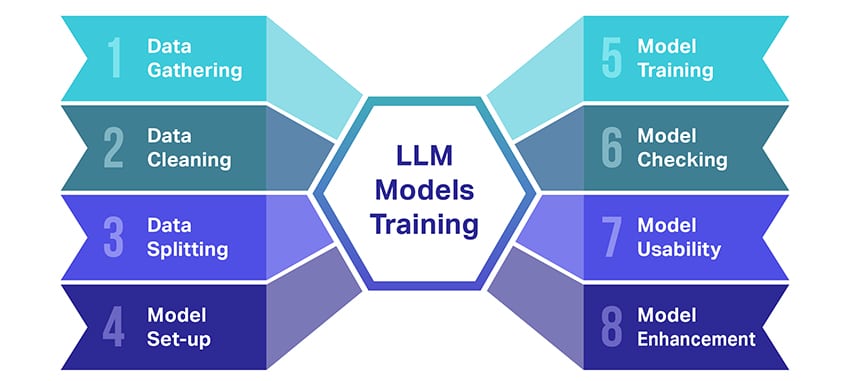
- စာသားဒေတာစုဆောင်းခြင်း LLM လေ့ကျင့်ရေးသည် များပြားလှသော စာသားဒေတာ စုဆောင်းမှုဖြင့် စတင်သည်။ ဤဒေတာသည် စာအုပ်များ၊ ဝဘ်ဆိုဒ်များ၊ ဆောင်းပါးများ၊ သို့မဟုတ် ဆိုရှယ်မီဒီယာပလပ်ဖောင်းများမှ လာနိုင်သည်။ ရည်ရွယ်ချက်မှာ လူ့ဘာသာစကား၏ များပြားလှသော ကွဲပြားမှုကို ဖမ်းယူရန်ဖြစ်သည်။
- ဒေတာရှင်းလင်းခြင်း ထို့နောက် စာသားဒေတာအကြမ်းကို ကြိုတင်လုပ်ဆောင်ခြင်းဟုခေါ်သော လုပ်ငန်းစဉ်တွင် သပ်ရပ်အောင်ပြုလုပ်သည်။ ၎င်းတွင် မလိုလားအပ်သော အက္ခရာများကို ဖယ်ရှားခြင်း၊ စာသားကို တိုကင်များဟုခေါ်သော အစိတ်အပိုင်းငယ်များအဖြစ် ခွဲခြမ်းခြင်းနှင့် ၎င်းကို မော်ဒယ်လ်ဖြင့် လုပ်ဆောင်နိုင်သော ဖော်မတ်တစ်ခုအဖြစ် ပြုလုပ်ခြင်းကဲ့သို့သော လုပ်ငန်းတာဝန်များ ပါဝင်သည်။
- ဒေတာခွဲထုတ်ခြင်း ထို့နောက် clean data ကို နှစ်စုံခွဲထားသည်။ မော်ဒယ်ကို လေ့ကျင့်ရန်အတွက် တစ်အုပ်တည်းဖြစ်သော လေ့ကျင့်ရေးဒေတာကို အသုံးပြုမည်ဖြစ်သည်။ မော်ဒယ်၏ စွမ်းဆောင်ရည်ကို စမ်းသပ်ရန် အခြားအစုံ၊ အတည်ပြုချက်ဒေတာကို နောက်ပိုင်းတွင် အသုံးပြုပါမည်။
- မော်ဒယ်ကို သတ်မှတ်ခြင်း- ဗိသုကာဟုလူသိများသော LLM ၏ဖွဲ့စည်းပုံကိုထို့နောက်သတ်မှတ်သည်။ ၎င်းတွင် အာရုံကြောကွန်ရက်အမျိုးအစားကို ရွေးချယ်ခြင်းနှင့် ကွန်ရက်အတွင်း အလွှာအရေအတွက်နှင့် လျှို့ဝှက်ယူနစ်များကဲ့သို့သော အမျိုးမျိုးသော ကန့်သတ်ဘောင်များကို ဆုံးဖြတ်ခြင်းတို့ ပါဝင်သည်။
- မော်ဒယ်သင်တန်း- အမှန်တကယ် လေ့ကျင့်မှု စတင်နေပါပြီ။ LLM မော်ဒယ်သည် လေ့ကျင့်ရေးဒေတာကိုကြည့်ရှုကာ၊ ယခုအချိန်အထိသင်ယူခဲ့သည့်အရာများအပေါ်အခြေခံ၍ ကြိုတင်ခန့်မှန်းမှုများပြုလုပ်ခြင်းနှင့် ၎င်း၏ခန့်မှန်းချက်နှင့်အမှန်တကယ်ဒေတာအကြားခြားနားချက်ကိုလျှော့ချရန်အတွက် ၎င်း၏အတွင်းပိုင်းဘောင်များကို ချိန်ညှိခြင်းဖြင့် သင်ယူသည်။
- Model ကိုစစ်ဆေးခြင်း။: LLM မော်ဒယ်၏ သင်ယူမှုကို အတည်ပြုခြင်းဒေတာကို အသုံးပြု၍ စစ်ဆေးသည်။ ၎င်းသည် မော်ဒယ်၏ စွမ်းဆောင်ရည် မည်မျှ ကောင်းမွန်သည်ကို သိမြင်နိုင်ပြီး ပိုမိုကောင်းမွန်သော စွမ်းဆောင်ရည်အတွက် မော်ဒယ်၏ ဆက်တင်များကို ပြုပြင်ပြောင်းလဲရန် ကူညီပေးသည်။
- Model ကိုအသုံးပြုခြင်း။သင်တန်းနှင့် အကဲဖြတ်ပြီးနောက်၊ LLM မော်ဒယ်သည် အသုံးပြုရန် အသင့်ဖြစ်နေပါပြီ။ ၎င်းအား ပေးထားသည့် သွင်းအားစုအသစ်များအပေါ် အခြေခံ၍ ၎င်းကို စာသားထုတ်ပေးမည့် အပလီကေးရှင်းများ သို့မဟုတ် စနစ်များတွင် ပေါင်းစည်းနိုင်ပါပြီ။
- မော်ဒယ်ကို မြှင့်တင်ခြင်း- နောက်ဆုံးအနေနဲ့ တိုးတက်မှုအတွက် နေရာအမြဲရှိတယ်။ တုံ့ပြန်ချက်နှင့် လက်တွေ့ကမ္ဘာအသုံးပြုမှုအပေါ်အခြေခံ၍ မွမ်းမံထားသောဒေတာကို အသုံးပြု၍ LLM မော်ဒယ်ကို အချိန်နှင့်အမျှ ပိုမိုသန့်စင်နိုင်ပါသည်။
ဤလုပ်ငန်းစဉ်သည် စွမ်းအားကြီးမားသော လုပ်ဆောင်မှုယူနစ်များနှင့် ကြီးမားသောသိုလှောင်မှုကဲ့သို့သော သိသာထင်ရှားသော တွက်ချက်မှုဆိုင်ရာအရင်းအမြစ်များ လိုအပ်ကြောင်း သတိရပါ၊ စက်သင်ယူခြင်းဆိုင်ရာ အထူးပြုအသိပညာများ လိုအပ်ပါသည်။ ထို့ကြောင့် လိုအပ်သော အခြေခံအဆောက်အဦနှင့် ကျွမ်းကျင်မှုဆိုင်ရာ သီးသန့် သုတေသနအဖွဲ့များ သို့မဟုတ် ကုမ္ပဏီများမှ ပြုလုပ်လေ့ရှိပါသည်။
LLM သည် ကြီးကြပ်မှု သို့မဟုတ် ကြီးကြပ်မထားသော သင်ယူမှုကို အားကိုးပါသလား။
ကြီးမားသော ဘာသာစကားပုံစံများကို အများအားဖြင့် ကြီးကြပ်သင်ကြားခြင်းဟုခေါ်သော နည်းလမ်းကို အသုံးပြု၍ လေ့ကျင့်သင်ကြားပေးပါသည်။ ရိုးရိုးရှင်းရှင်းပြောရရင်၊ ဒါက အဖြေမှန်ကိုပြတဲ့ ဥပမာတွေကနေ သင်ယူတာကို ဆိုလိုတာပါ။
 သူတို့ကို ပုံတွေပြပြီး ကလေးစကားတွေကို သင်ပေးနေတယ်လို့ မြင်ယောင်ကြည့်ပါ။ မင်းသူတို့ကို ကြောင်ရုပ်ပုံပြပြီး "ကြောင်" လို့ပြောပြီး အဲဒီရုပ်ပုံကို စကားလုံးနဲ့ တွဲဖို့ သင်ယူကြတယ်။ အဲဒါက ကြီးကြပ်မှု သင်ယူမှု အလုပ်ဖြစ်တယ်။ မော်ဒယ်သည် စာသားများစွာ (“ရုပ်ပုံများ”) နှင့် သက်ဆိုင်သော ရလဒ်များ (“စကားလုံးများ”) ကိုပေးထားပြီး ၎င်းတို့နှင့် ကိုက်ညီရန် သင်ယူသည်။
သူတို့ကို ပုံတွေပြပြီး ကလေးစကားတွေကို သင်ပေးနေတယ်လို့ မြင်ယောင်ကြည့်ပါ။ မင်းသူတို့ကို ကြောင်ရုပ်ပုံပြပြီး "ကြောင်" လို့ပြောပြီး အဲဒီရုပ်ပုံကို စကားလုံးနဲ့ တွဲဖို့ သင်ယူကြတယ်။ အဲဒါက ကြီးကြပ်မှု သင်ယူမှု အလုပ်ဖြစ်တယ်။ မော်ဒယ်သည် စာသားများစွာ (“ရုပ်ပုံများ”) နှင့် သက်ဆိုင်သော ရလဒ်များ (“စကားလုံးများ”) ကိုပေးထားပြီး ၎င်းတို့နှင့် ကိုက်ညီရန် သင်ယူသည်။
ထို့ကြောင့်၊ သင်သည် LLM တစ်ခုကို ဝါကျတစ်ခုအား ကျွေးပါက၊ ၎င်းသည် နမူနာများမှ သင်ယူခဲ့ရာများကို အခြေခံ၍ နောက်စကားလုံး သို့မဟုတ် စကားစုကို ခန့်မှန်းရန် ကြိုးစားသည်။ ဤနည်းဖြင့်၊ ၎င်းသည် အဓိပ္ပာယ်ရှိပြီး အကြောင်းအရာနှင့်ကိုက်ညီသော စာသားကို မည်သို့ထုတ်လုပ်ရမည်ကို လေ့လာသည်။
ဆိုလိုသည်မှာ၊ တစ်ခါတစ်ရံ LLM များသည် ကြီးကြပ်မထားသော သင်ယူမှုအနည်းငယ်ကိုလည်း အသုံးပြုပါသည်။ ဒါက ကလေးကို မတူညီတဲ့ ကစားစရာတွေနဲ့ ပြည့်နေတဲ့ အခန်းကို စူးစမ်းလေ့လာပြီး သူတို့ဘာသာ သူတို့အကြောင်း လေ့လာခွင့်ပေးလိုက်တာနဲ့ တူပါတယ်။ မော်ဒယ်သည် တံဆိပ်မပါသော ဒေတာ၊ သင်ယူမှုပုံစံများနှင့် "မှန်" အဖြေများကို မပြောဘဲ ကြည့်ရှုသည်။
ကြီးကြပ်ထားသော သင်ယူမှုသည် တံဆိပ်တပ်ထားသော အထွက်ဒေတာကို အသုံးမပြုသည့် ကြီးကြပ်မထားသော သင်ယူမှုနှင့် ဆန့်ကျင်ဘက်အားဖြင့် သွင်းအားစုများနှင့် အထွက်များဟု အညွှန်းတပ်ထားသော ဒေတာကို အသုံးပြုသည်။
အတိုချုပ်အားဖြင့်၊ LLM များသည် ကြီးကြပ်သင်ကြားမှုကို အသုံးပြု၍ အဓိကအားဖြင့် လေ့ကျင့်သင်ကြားထားသော်လည်း ၎င်းတို့သည် စူးစမ်းလေ့လာခွဲခြမ်းစိတ်ဖြာခြင်းနှင့် အတိုင်းအတာလျှော့ချခြင်းကဲ့သို့သော ၎င်းတို့၏စွမ်းရည်များကို မြှင့်တင်ရန်အတွက် ကြီးကြပ်မထားသော သင်ယူမှုကိုလည်း အသုံးပြုနိုင်သည်။
ကြီးမားသောဘာသာစကားပုံစံတစ်ခုကို လေ့ကျင့်ရန် ဒေတာပမာဏ (GB) သည် အဘယ်နည်း။
စကားပြောဒေတာ အသိအမှတ်ပြုခြင်းနှင့် အသံအသုံးချခြင်းအတွက် ဖြစ်နိုင်ခြေရှိသော ကမ္ဘာသည် ကြီးမားပြီး ၎င်းတို့ကို အသုံးချမှုများစွာအတွက် လုပ်ငန်းအများအပြားတွင် အသုံးပြုလျက်ရှိသည်။
ကြီးမားသောဘာသာစကားပုံစံတစ်ခုကို လေ့ကျင့်သင်ကြားခြင်းသည် အထူးသဖြင့် လိုအပ်သောဒေတာနှင့်ပတ်သက်လာသောအခါ အရွယ်အစားတစ်ခုတည်း-အံဝင်ခွင်ကျ-အားလုံးလုပ်ဆောင်သည့်လုပ်ငန်းစဉ်မဟုတ်ပါ။ အရာများစွာပေါ်တွင်မူတည်သည်-
- မော်ဒယ်ဒီဇိုင်း။
- ဘာအလုပ်လုပ်ရမှာလဲ။
- သင်အသုံးပြုနေသော ဒေတာအမျိုးအစား။
- ဘယ်လောက်ကောင်းအောင် စွမ်းဆောင်ချင်လဲ။
ဆိုလိုသည်မှာ၊ လေ့ကျင့်ရေး LLM များသည် များသောအားဖြင့် စာသားဒေတာများစွာ လိုအပ်သည်။ ဒါပေမယ့် ငါတို့ပြောနေတာ ဘယ်လောက်ကြီးလဲ။ ကောင်းပြီ၊ ဂစ်ဂါဘိုက် (GB) ထက်ကျော်လွန်၍ စဉ်းစားပါ။ ကျွန်ုပ်တို့သည် ဒေတာ၏ terabytes (TB) သို့မဟုတ် petabytes (PB) ကိုပင် ကြည့်ရှုလေ့ရှိသည်။
ပတ်ဝန်းကျင်တွင် အကြီးဆုံး LLM များထဲမှ တစ်ခုဖြစ်သော GPT-3 ကို သုံးသပ်ကြည့်ပါ။ အဲဒါကို လေ့ကျင့်ထားတယ်။ 570 GB စာသားဒေတာ. သေးငယ်သော LLM များသည် 10-20 GB သို့မဟုတ် 1 GB of gigabyte ပင် လိုအပ်နိုင်သည် - သို့သော် ၎င်းသည် များစွာရှိပါသေးသည်။

ဒါပေမယ့် အချက်အလက် အရွယ်အစားလောက်တော့ မဟုတ်ပါဘူး။ အရည်အသွေးလည်း အရေးကြီးတယ်။ မော်ဒယ်ကို ထိထိရောက်ရောက် လေ့လာနိုင်ရန် ဒေတာများသည် သန့်ရှင်းပြီး ကွဲပြားရန် လိုအပ်ပါသည်။ ပြီးတော့ သင်လိုအပ်တဲ့ ကွန်ပြူတာစွမ်းအင်၊ လေ့ကျင့်မှုအတွက် သင်အသုံးပြုတဲ့ algorithms နဲ့ သင့်မှာရှိနေတဲ့ hardware setup တွေလိုမျိုး ပဟေဋ္ဌိတွေရဲ့ တခြားသော့ချက်အပိုင်းတွေကို သင်မေ့ထားလို့မရပါဘူး။ ဤအချက်များအားလုံးသည် LLM လေ့ကျင့်ရေးတွင် ကြီးမားသောအစိတ်အပိုင်းတစ်ခုဖြစ်သည်။
ကြီးမားသောဘာသာစကားမော်ဒယ်များ ထွန်းကားလာခြင်း- သူတို့ဘာကြောင့် အရေးကြီးတာလဲ။
LLM များသည် အယူအဆတစ်ခု သို့မဟုတ် စမ်းသပ်မှုတစ်ခုမျှသာ မဟုတ်တော့ပါ။ ၎င်းတို့သည် ကျွန်ုပ်တို့၏ ဒစ်ဂျစ်တယ် အခင်းအကျင်းတွင် အရေးပါသော အခန်းကဏ္ဍမှ ပိုမိုပါဝင်လာပါသည်။ ဒါပေမယ့် ဘာကြောင့် ဒီလိုဖြစ်နေတာလဲ။ ဤ LLM များသည် အဘယ်အရာက အလွန်အရေးကြီးသနည်း။ အဓိကအချက်အချို့ကို လေ့လာကြည့်ရအောင်။
လူ့စာသားကို အတုခိုးခြင်းတွင် ကျွမ်းကျင်သည်။
LLM များသည် ကျွန်ုပ်တို့၏ ဘာသာစကားအခြေခံ လုပ်ဆောင်ချက်များကို ကိုင်တွယ်ပုံ ပြောင်းလဲလာပါသည်။ ခိုင်မာသော စက်သင်ယူမှု အယ်လဂိုရီသမ်များကို အသုံးပြု၍ တည်ဆောက်ထားသော ဤမော်ဒယ်များသည် အကြောင်းအရာ၊ စိတ်ခံစားမှုနှင့် ထေ့ငေါ့ခြင်းအပါအဝင် လူ့ဘာသာစကား၏ ကွဲပြားချက်များကို နားလည်နိုင်စွမ်း အတိုင်းအတာတစ်ခုအထိ တပ်ဆင်ထားပါသည်။ လူ့ဘာသာစကားကို အတုယူနိုင်သော ဤစွမ်းရည်သည် အသစ်အဆန်းမျှသာမဟုတ်ပါ၊ ၎င်းတွင် သိသာထင်ရှားသောသက်ရောက်မှုများရှိသည်။
LLMs ၏ အဆင့်မြင့် စာသားဖန်တီးမှုစွမ်းရည်များသည် အကြောင်းအရာဖန်တီးမှုမှ ဖောက်သည်ဝန်ဆောင်မှု အပြန်အလှန်ဆက်သွယ်မှုများအထိ အရာအားလုံးကို မြှင့်တင်ပေးနိုင်ပါသည်။
ဒစ်ဂျစ်တယ်လက်ထောက်တစ်ဦးအား ရှုပ်ထွေးသောမေးခွန်းတစ်ခုမေးနိုင်ပြီး အဓိပ္ပါယ်ရှိရုံသာမက ပေါင်းစပ်၊ ဆီလျော်မှုရှိကာ စကားစမြည်အသံဖြင့် ပေးပို့နိုင်သည်ဟု စိတ်ကူးကြည့်ပါ။ အဲဒါက LLM တွေကို ဖွင့်ပေးတယ်။ ၎င်းတို့သည် ပိုမိုနားလည်သဘောပေါက်ပြီး ဆွဲဆောင်မှုရှိသော လူသားစက်ဖြင့် အပြန်အလှန်တုံ့ပြန်မှု၊ သုံးစွဲသူအတွေ့အကြုံများကို ကြွယ်ဝစေကာ သတင်းအချက်အလက်ရယူခွင့်ကို ဒီမိုကရေစီအသွင်ကူးပြောင်းရေးကို လှုံ့ဆော်ပေးလျက်ရှိသည်။
တတ်နိုင်သော ကွန်ပျူတာစွမ်းအား
ကွန်ပြူတာနယ်ပယ်တွင် အပြိုင်ဖြစ်ထွန်းမှုများမရှိဘဲ LLM များ တိုးလာခြင်းသည် မဖြစ်နိုင်ပါ။ အထူးသဖြင့်၊ တွက်ချက်မှုဆိုင်ရာ အရင်းအမြစ်များကို ဒီမိုကရက်တစ်ကူးပြောင်းခြင်းသည် LLMs များ ဆင့်ကဲပြောင်းလဲခြင်းနှင့် လက်ခံကျင့်သုံးခြင်းတွင် အရေးပါသောအခန်းကဏ္ဍမှ ပါဝင်ခဲ့သည်။
Cloud-based ပလပ်ဖောင်းများသည် စွမ်းဆောင်ရည်မြင့်မားသော ကွန်ပြူတာအရင်းအမြစ်များကို မကြုံစဖူးဝင်ရောက်ခွင့်ပေးထားပါသည်။ ဤနည်းအားဖြင့် အသေးစားအဖွဲ့အစည်းများနှင့် အမှီအခိုကင်းသော သုတေသီများပင်လျှင် ခေတ်မီဆန်းပြားသော စက်သင်ယူမှုပုံစံများကို လေ့ကျင့်ပေးနိုင်ပါသည်။
ထို့အပြင်၊ ဖြန့်ဝေထားသော ကွန်ပြူတာများ ထွန်းကားလာခြင်းနှင့် ပေါင်းစပ်လိုက်သော လုပ်ဆောင်မှုယူနစ်များ (GPUs နှင့် TPUs များကဲ့သို့) တိုးတက်မှုများသည် ကန့်သတ်ဘောင်ပေါင်းများစွာဖြင့် မော်ဒယ်များကို လေ့ကျင့်နိုင်စေခဲ့သည်။ ကွန်ပြူတာစွမ်းအား၏ တိုးမြှင့်သုံးစွဲနိုင်မှုသည် LLMs များ၏ တိုးတက်မှုနှင့် အောင်မြင်မှုကို အထောက်အပံ့ဖြစ်စေပြီး နယ်ပယ်တွင် ဆန်းသစ်တီထွင်မှုနှင့် အသုံးချပရိုဂရမ်များကို ပိုမိုဖြစ်ပေါ်စေသည်။
စားသုံးသူအကြိုက်များပြောင်းခြင်း။
ယနေ့ စားသုံးသူများသည် အဖြေကို မလိုချင်ကြပါ။ သူတို့သည် ထိတွေ့ဆက်ဆံမှုနှင့် ဆက်စပ်သော အပြန်အလှန်တုံ့ပြန်မှုများကို လိုချင်ကြသည်။ ဒစ်ဂျစ်တယ်နည်းပညာကို အသုံးပြု၍ လူများ ကြီးပြင်းလာသည်နှင့်အမျှ ပိုမိုသဘာဝကျပြီး လူသားနှင့်တူသည်ဟု ခံစားရနိုင်သော နည်းပညာလိုအပ်မှု တိုးလာကြောင်း ထင်ရှားပါသည်။ LLMs များသည် အဆိုပါမျှော်လင့်ချက်များကို ပြည့်မီရန် တုနှိုင်းမဲ့အခွင့်အရေးကို ပေးဆောင်ပါသည်။ လူနှင့်တူသော စာသားများကို ဖန်တီးခြင်းဖြင့်၊ ဤမော်ဒယ်များသည် သုံးစွဲသူများ၏ စိတ်ကျေနပ်မှုနှင့် သစ္စာစောင့်သိမှုကို တိုးမြင့်စေနိုင်သည့် ဆွဲဆောင်မှုရှိပြီး တက်ကြွသော ဒစ်ဂျစ်တယ်အတွေ့အကြုံများကို ဖန်တီးနိုင်သည်။ ဖောက်သည်ဝန်ဆောင်မှုပေးသည့် AI chatbots များ သို့မဟုတ် သတင်းအပ်ဒိတ်များကို ပံ့ပိုးပေးသည့် အသံအကူများဖြစ်စေ LLM များသည် ကျွန်ုပ်တို့ကို ပိုမိုကောင်းမွန်စွာနားလည်နိုင်သော AI ခေတ်တွင် စတင်လာပါသည်။
Unstructured Data Goldmine
အီးမေးလ်များ၊ ဆိုရှယ်မီဒီယာပို့စ်များနှင့် ဝယ်ယူသူသုံးသပ်ချက်များကဲ့သို့သော ဖွဲ့စည်းပုံမရှိသောဒေတာသည် ထိုးထွင်းသိမြင်နိုင်သော ရတနာသိုက်တစ်ခုဖြစ်သည်။ ပြီးသွားပြီလို့ ခန့်မှန်းရပါတယ်။ 80% လုပ်ငန်းဒေတာများသည် ဖွဲ့စည်းပုံမညီဘဲ နှုန်းဖြင့် ကြီးထွားလာသည်။ 55% တစ်နှစ်လျှင်။ မှန်ကန်စွာ အသုံးချပါက ဤဒေတာသည် စီးပွားရေးလုပ်ငန်းများအတွက် ရွှေတွင်းဖြစ်သည်။
LLM များသည် ၎င်းတို့လုပ်ဆောင်နိုင်စွမ်းရှိပြီး ထိုသို့သောဒေတာများကို အတိုင်းအတာတစ်ခုအထိ နားလည်သဘောပေါက်နိုင်စွမ်းဖြင့် ဤနေရာတွင် ပါဝင်ကစားပါသည်။ ၎င်းတို့သည် စိတ်ဓာတ်များကို ခွဲခြမ်းစိတ်ဖြာခြင်း၊ စာသားအမျိုးအစားခွဲခြားခြင်း၊ အချက်အလက်များ ထုတ်ယူခြင်းနှင့် အခြားအရာများကဲ့သို့သော လုပ်ငန်းဆောင်တာများကို ကိုင်တွယ်ဆောင်ရွက်နိုင်ပြီး တန်ဖိုးရှိသော ထိုးထွင်းသိမြင်မှုများကို ပေးစွမ်းနိုင်သည်။
ဆိုရှယ်မီဒီယာပို့စ်များမှ ခေတ်ရေစီးကြောင်းများကို ခွဲခြားသတ်မှတ်ခြင်း သို့မဟုတ် ပြန်လည်သုံးသပ်ခြင်းမှ သုံးစွဲသူများ၏ သဘောထားကို တိုင်းတာခြင်းဖြစ်စေ LLM များသည် လုပ်ငန်းများကို ဖွဲ့စည်းတည်ဆောက်ပုံမထားသောဒေတာအများအပြားကို လမ်းညွှန်ပြသကာ ဒေတာမောင်းနှင်သည့် ဆုံးဖြတ်ချက်များချနိုင်ရန် ကူညီပေးပါသည်။
NLP စျေးကွက်ချဲ့ထွင်ခြင်း။
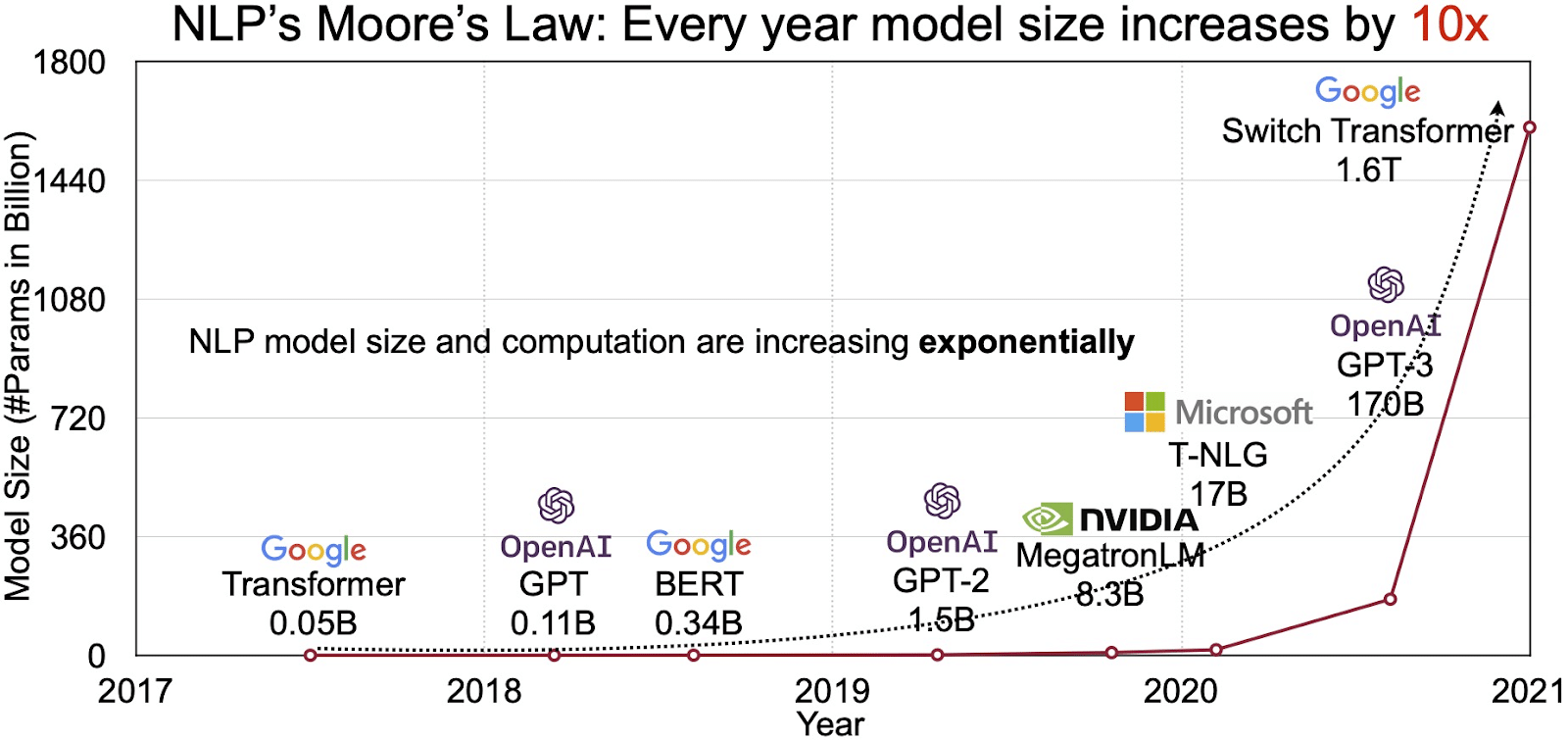
LLM များ၏ အလားအလာသည် လျင်မြန်စွာကြီးထွားလာနေသော သဘာဝဘာသာစကားလုပ်ဆောင်ခြင်း (NLP) စျေးကွက်တွင် ထင်ဟပ်နေသည်။ လေ့လာသုံးသပ်သူများသည် NLP စျေးကွက်မှတိုးချဲ့ရန်ပရောဂျက် 11 တွင် $ 2020 billion မှ 35 တွင် $2026 billion ကျော်ရှိသည်။. ဒါပေမယ့် စျေးကွက်ချဲ့ထွင်ရုံတင်မကပါဘူး။ မော်ဒယ်များကိုယ်တိုင်ကလည်း ရုပ်ပိုင်းဆိုင်ရာ အရွယ်အစားနှင့် ၎င်းတို့ကိုင်တွယ်သည့် ကန့်သတ်ချက်များ အရေအတွက်အရ ကြီးထွားလာသည်။ အောက်ဖော်ပြပါပုံတွင်တွေ့ရသည့်အတိုင်း LLM များ၏ ဆင့်ကဲပြောင်းလဲမှုသည် နှစ်များတစ်လျှောက် (ပုံအရင်းအမြစ်- လင့်ခ်) သည် ၎င်းတို့၏ တိုးလာနေသော ရှုပ်ထွေးမှုနှင့် စွမ်းရည်ကို အလေးပေးဖော်ပြသည်။
ကြီးမားသောဘာသာစကားမော်ဒယ်များ၏ လူကြိုက်များသောအသုံးပြုမှုကိစ္စများ
ဤသည်မှာ LLM ၏ ထိပ်တန်းနှင့် အဖြစ်အများဆုံး အသုံးပြုမှုကိစ္စရပ်အချို့ဖြစ်သည်။
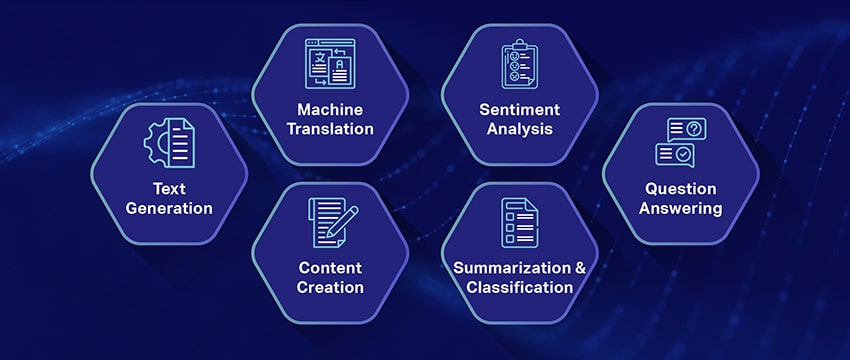
- သဘာဝဘာသာစကားစာသားကို ထုတ်လုပ်ခြင်း- ကြီးမားသောဘာသာစကားပုံစံများ (LLMs) သည် သဘာဝဘာသာစကားဖြင့် စာသားများကို အလိုအလျောက်ထုတ်လုပ်နိုင်ရန် ဉာဏ်ရည်တုနှင့် တွက်ချက်မှုဆိုင်ရာဘာသာဗေဒ၏ စွမ်းအားကို ပေါင်းစပ်ထားသည်။ ဆောင်းပါးများရေးသားခြင်း၊ သီချင်းများဖန်တီးခြင်း၊ သို့မဟုတ် အသုံးပြုသူများနှင့် စကားစမြည်ပြောဆိုခြင်းကဲ့သို့သော အမျိုးမျိုးသောအသုံးပြုသူလိုအပ်ချက်များကို ဖြည့်ဆည်းပေးနိုင်ပါသည်။
- စက်များဖြင့် ဘာသာပြန်ခြင်း မည်သည့်ဘာသာစကားတစ်စုံကြားတွင်မဆို စာသားကို ဘာသာပြန်ရန် LLM များကို ထိရောက်စွာအသုံးပြုနိုင်ပါသည်။ ဤမော်ဒယ်များသည် အရင်းအမြစ်နှင့် ပစ်မှတ်ဘာသာစကားနှစ်ခုလုံး၏ ဘာသာစကားဖွဲ့စည်းပုံကို နားလည်ရန် ထပ်တလဲလဲ အာရုံကြောကွန်ရက်များကဲ့သို့ နက်နဲသောသင်ယူမှုဆိုင်ရာ အယ်လဂိုရီသမ်များကို အသုံးချကာ အရင်းအမြစ်စာသားကို အလိုရှိသောဘာသာစကားသို့ ဘာသာပြန်ဆိုရာတွင် လွယ်ကူချောမွေ့စေပါသည်။
- မူရင်းအကြောင်းအရာကို ဖန်တီးခြင်း- LLM များသည် စည်းလုံးညီညွတ်ပြီး ယုတ္တိတန်သော အကြောင်းအရာများကို ထုတ်လုပ်ရန် စက်များအတွက် လမ်းဖွင့်ပေးထားသည်။ ဤအကြောင်းအရာကို ဘလော့ဂ်ပို့စ်များ၊ ဆောင်းပါးများနှင့် အခြားအကြောင်းအရာအမျိုးအစားများ ဖန်တီးရန်အတွက် အသုံးပြုနိုင်ပါသည်။ မော်ဒယ်များသည် အကြောင်းအရာကို ဆန်းသစ်ပြီး အသုံးပြုရလွယ်ကူသောပုံစံဖြင့် ဖော်မတ်ဖွဲ့စည်းတည်ဆောက်ရန် ၎င်းတို့၏ လေးနက်သော နက်နဲသော သင်ယူမှုအတွေ့အကြုံသို့ နှိပ်ပါ။
- ခံစားချက်များကို ပိုင်းခြားစိတ်ဖြာခြင်း- Large Language Models ၏ စွဲမက်ဖွယ်ကောင်းသော အသုံးချမှုတစ်ခုမှာ စိတ်ဓာတ်ပိုင်းဆိုင်ရာ ခွဲခြမ်းစိတ်ဖြာခြင်း ဖြစ်သည်။ ဤတွင်၊ သရုပ်ဖော်ထားသောစာသားတွင်ပါရှိသော စိတ်ခံစားမှုအခြေအနေများနှင့် ခံစားချက်များကို ခွဲခြားသိမြင်ရန်နှင့် အမျိုးအစားခွဲရန် မော်ဒယ်ကို လေ့ကျင့်ထားသည်။ ဆော့ဖ်ဝဲသည် အကောင်းမြင်စိတ်၊ အဆိုးမြင်စိတ်၊ ကြားနေမှုနှင့် အခြားရှုပ်ထွေးသော ခံစားချက်များကဲ့သို့သော စိတ်ခံစားမှုများကို ခွဲခြားသတ်မှတ်နိုင်သည်။ ၎င်းသည် ထုတ်ကုန်များနှင့် ဝန်ဆောင်မှုအမျိုးမျိုးအကြောင်း ဖောက်သည်တုံ့ပြန်ချက်နှင့် အမြင်များကို တန်ဖိုးရှိသော ထိုးထွင်းသိမြင်မှုကို ပေးစွမ်းနိုင်သည်။
- နားလည်ခြင်း၊ အကျဉ်းချုပ်ခြင်းနှင့် စာသားအမျိုးအစားခွဲခြားခြင်း- LLM များသည် စာသားနှင့် ၎င်း၏အကြောင်းအရာကို အဓိပ္ပာယ်ပြန်ဆိုရန် AI ဆော့ဖ်ဝဲလ်အတွက် အသုံးဝင်သော ဖွဲ့စည်းပုံကို ထူထောင်သည်။ ဒေတာအများအပြားကို နားလည်ပြီး စိစစ်ရန် မော်ဒယ်ကို ညွှန်ကြားခြင်းဖြင့်၊ LLMs များသည် AI မော်ဒယ်များကို နားလည်နိုင်၊ အကျဉ်းချုပ်ကာ ကွဲပြားသောပုံစံများနှင့် ပုံစံများဖြင့် စာသားများကို အမျိုးအစားခွဲနိုင်စေပါသည်။
- မေးခွန်းများဖြေဆိုခြင်း- ကြီးမားသောဘာသာစကားမော်ဒယ်များသည် အသုံးပြုသူ၏သဘာဝဘာသာစကားမေးမြန်းမှုအား တိကျစွာသိရှိနားလည်ပြီး တုံ့ပြန်နိုင်သည့်စွမ်းရည်ဖြင့် မေးခွန်းဖြေဆိုခြင်း (QA) စနစ်များကို တပ်ဆင်ပေးပါသည်။ ဤအသုံးပြုမှုကိစ္စ၏ လူကြိုက်များသောဥပမာများတွင် ChatGPT နှင့် BERT တို့ပါဝင်သည်၊ ၎င်းသည် မေးမြန်းမှုတစ်ခု၏အကြောင်းအရာကို ဆန်းစစ်ကာ သုံးစွဲသူမေးခွန်းများအတွက် သက်ဆိုင်ရာအဖြေများပေးဆောင်ရန် စာတိုပေါင်းများစွာကို စုစည်းကာ ခွဲခြမ်းစိပ်ဖြာပေးသည်။

Part-of-Speech (POS) Tagging
ဝါကျများရှိ စကားလုံးများကို ကြိယာများ၊ နာမ်များ၊ နာမဝိသေသနများ စသည်တို့ကဲ့သို့ ၎င်းတို့၏ သဒ္ဒါလုပ်ဆောင်ချက်ဖြင့် တဂ်ထားသည်။ ဤလုပ်ငန်းစဉ်သည် သဒ္ဒါနှင့် စကားလုံးများကြား ဆက်စပ်မှုများကို နားလည်နိုင်စေရန် နမူနာအား ကူညီပေးပါသည်။

Named Entity အသိအမှတ်ပြုခြင်း (NER)
အဖွဲ့အစည်းများ၊ တည်နေရာများနှင့် ဝါကျတစ်ခုအတွင်းရှိ လူများကဲ့သို့ အမည်ပေးထားသော အရာများကို အမှတ်အသားပြုထားသည်။ ဤလေ့ကျင့်ခန်းသည် မော်ဒယ်အား စကားလုံးများနှင့် စကားစုများ၏ အနက်အဓိပ္ပါယ်များကို အဓိပ္ပာယ်ပြန်ဆိုရာတွင် အထောက်အကူဖြစ်ပြီး ပိုမိုတိကျသောတုံ့ပြန်မှုများကို ပေးပါသည်။

စိတ်ဓါတ်ခွဲခြမ်းစိတ်ဖြာ
စာသားဒေတာကို အပြုသဘော၊ ဘက်မလိုက်၊ သို့မဟုတ် အဆိုးမြင်ခြင်းကဲ့သို့သော ခံစားချက်အညွှန်းများကို သတ်မှတ်ပေးထားပြီး မော်ဒယ်သည် စာကြောင်းများ၏ စိတ်ခံစားမှုဆိုင်ရာ တီးတိုးကို ဖမ်းဆုပ်နိုင်ရန် ကူညီပေးသည်။ စိတ်ခံစားမှုများနှင့် ထင်မြင်ယူဆချက်များ ပါ၀င်သည့် မေးခွန်းများကို တုံ့ပြန်ရာတွင် အထူးအသုံးဝင်သည်။
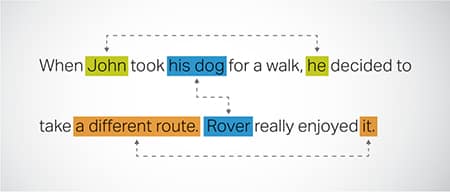
Coreference Resolution
တူညီသောအကြောင်းအရာကို စာသားတစ်ခု၏ မတူညီသော အစိတ်အပိုင်းများတွင် ရည်ညွှန်းသည့် ဖြစ်ရပ်များကို ခွဲခြားသတ်မှတ်ခြင်းနှင့် ဖြေရှင်းခြင်း။ ဤအဆင့်သည် မော်ဒယ်အား ဝါကျ၏အကြောင်းအရာကို နားလည်စေပြီး ပေါင်းစပ်တုံ့ပြန်မှုများကို ဖြစ်ပေါ်စေသည်။
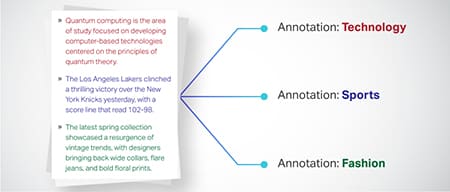
စာသားခွဲခြား
စာသားဒေတာကို ထုတ်ကုန်သုံးသပ်ချက် သို့မဟုတ် သတင်းဆောင်းပါးများကဲ့သို့ ကြိုတင်သတ်မှတ်ထားသော အုပ်စုများအဖြစ် အမျိုးအစားခွဲထားသည်။ ၎င်းသည် စာသားအမျိုးအစား သို့မဟုတ် အကြောင်းအရာကို ပိုင်းခြားသိမြင်ရန် မော်ဒယ်အား ကူညီပေးပြီး ပိုမိုသက်ဆိုင်သော တုံ့ပြန်မှုများကို ဖန်တီးပေးပါသည်။
Shaip ပူဇော်သက္ကာ
ship အဖွဲ့အစည်းများအား စီမံခန့်ခွဲခြင်း၊ ခွဲခြမ်းစိတ်ဖြာခြင်းနှင့် ၎င်းတို့၏ဒေတာကို အများဆုံးအသုံးပြုရန် ဝန်ဆောင်မှုများစွာကို ပံ့ပိုးပေးပါသည်။
ဒေတာ Web-Scraping
Shaip မှပေးဆောင်သော အဓိကဝန်ဆောင်မှုတစ်ခုမှာ ဒေတာဖြုန်းတီးခြင်းပင်ဖြစ်သည်။ ၎င်းတွင် domain-specific URLs များမှ ဒေတာထုတ်ယူခြင်း ပါဝင်သည်။ အလိုအလျောက် ကိရိယာများနှင့် နည်းစနစ်များကို အသုံးပြုခြင်းဖြင့် Shaip သည် ဝဘ်ဆိုက်များ၊ ထုတ်ကုန်လက်စွဲစာအုပ်များ၊ နည်းပညာမှတ်တမ်းများ၊ အွန်လိုင်းဖိုရမ်များ၊ အွန်လိုင်းသုံးသပ်ချက်များ၊ ဖောက်သည်ဝန်ဆောင်မှုဒေတာ၊ စက်မှုစည်းမျဉ်းစည်းကမ်းစာရွက်စာတမ်းများ စသည်တို့မှ ဒေတာအများအပြားကို လျင်မြန်ထိရောက်စွာ ခြစ်ထုတ်နိုင်ပါသည်။ အရင်းအမြစ်များစွာမှ သက်ဆိုင်ရာနှင့် သီးခြားအချက်အလက်များကို စုဆောင်းခြင်း။

စက်ဘာသာပြန်ခြင်း
ဘာသာစကားမျိုးစုံဖြင့် စာသားများကို ဘာသာပြန်ဆိုရန်အတွက် သက်ဆိုင်ရာ စာသားမှတ်တမ်းများနှင့် တွဲစပ်ထားသော ကျယ်ပြန့်သော ဘာသာစကားမျိုးစုံဒေတာအတွဲများကို အသုံးပြု၍ မော်ဒယ်များကို တီထွင်ပါ။ ဤလုပ်ငန်းစဉ်သည် ဘာသာစကားဆိုင်ရာ အတားအဆီးများကို ဖယ်ရှားစေပြီး သတင်းအချက်အလက်များ၏ လက်လှမ်းမီမှုကို အားပေးကူညီသည်။
Taxonomy Extraction & Creation
Shaip သည် အခွန်စည်းကြပ်မှု ထုတ်ယူခြင်းနှင့် ဖန်တီးခြင်းတွင် ကူညီနိုင်သည်။ ၎င်းတွင် မတူညီသော ဒေတာအချက်များကြားရှိ ဆက်ဆံရေးများကို ထင်ဟပ်စေသည့် ဖွဲ့စည်းပုံပုံစံတစ်ခုအဖြစ် ဒေတာများကို အမျိုးအစားခွဲခြားခြင်းနှင့် အမျိုးအစားခွဲခြင်းတို့ ပါဝင်ပါသည်။ ၎င်းသည် ၎င်းတို့၏ဒေတာများကို စုစည်းရာတွင် စီးပွားရေးလုပ်ငန်းများအတွက် အထူးအသုံးဝင်ပြီး ၎င်းကို ပိုမိုဝင်ရောက်ကြည့်ရှုနိုင်ကာ ခွဲခြမ်းစိတ်ဖြာရန် ပိုမိုလွယ်ကူစေသည်။ ဥပမာအားဖြင့်၊ e-commerce လုပ်ငန်းတစ်ခုတွင်၊ ထုတ်ကုန်ဒေတာကို ထုတ်ကုန်အမျိုးအစား၊ အမှတ်တံဆိပ်၊ စျေးနှုန်းစသည်ဖြင့် အမျိုးအစားခွဲနိုင်ပြီး သုံးစွဲသူများအတွက် ထုတ်ကုန်ကတ်တလောက်ကို သွားလာရန် ပိုမိုလွယ်ကူစေပါသည်။
ဒေတာများစုစည်းမှု
ကျွန်ုပ်တို့၏ ဒေတာစုဆောင်းခြင်းဝန်ဆောင်မှုများသည် သင့်မော်ဒယ်များ၏ တိကျမှုနှင့် ထိရောက်မှုတို့ကို မြှင့်တင်ပေးရန်အတွက် အရေးကြီးသော လက်တွေ့ကမ္ဘာ သို့မဟုတ် ပေါင်းစပ်ထားသော အချက်အလက်များကို ပံ့ပိုးပေးပါသည်။ ဒေတာကိုယ်ရေးကိုယ်တာနှင့် လုံခြုံရေးကို သတိရနေချိန်တွင် ဒေတာသည် ဘက်မလိုက်ဘဲ၊ ကျင့်ဝတ်အရနှင့် တာဝန်သိစွာ ရင်းမြစ်ဖြစ်သည်။

အမေးနှင့်အဖြေ
မေးခွန်းဖြေဆိုခြင်း (QA) သည် လူသားဘာသာစကားဖြင့် မေးခွန်းများကို အလိုအလျောက်ဖြေဆိုခြင်းအပေါ် အာရုံစိုက်လုပ်ဆောင်သည့် သဘာဝဘာသာစကားဖြင့် လုပ်ဆောင်ခြင်း၏ နယ်ပယ်ခွဲတစ်ခုဖြစ်သည်။ QA စနစ်များကို ကျယ်ကျယ်ပြန့်ပြန့် စာသားနှင့် ကုဒ်ပေါ်တွင် လေ့ကျင့်သင်ကြားထားပြီး အဖြစ်မှန်၊ အဓိပ္ပါယ်ဖွင့်ဆိုချက်များနှင့် ထင်မြင်ယူဆချက်များကို အခြေခံသည့် မေးခွန်းများအပါအဝင် မေးခွန်းအမျိုးအစားအမျိုးမျိုးကို ကိုင်တွယ်နိုင်စေပါသည်။ ဖောက်သည်ပံ့ပိုးမှု၊ ကျန်းမာရေးစောင့်ရှောက်မှု သို့မဟုတ် ထောက်ပံ့ရေးကွင်းဆက်ကဲ့သို့သော သီးခြားနယ်ပယ်များနှင့်အံဝင်ခွင်ကျဖြစ်စေသော QA မော်ဒယ်များကို တီထွင်ရန်အတွက် Domain အသိပညာသည် အရေးကြီးပါသည်။ သို့သော်၊ မျိုးဆက်သစ် QA ချဉ်းကပ်မှုများသည် စာသားများကို ဒိုမိန်းအသိပညာမပါဘဲ မော်ဒယ်များကို ဖန်တီးခွင့်ပြုကာ အကြောင်းအရာပေါ်တွင်သာ မှီခိုနေပါသည်။
ကျွန်ုပ်တို့၏ ကျွမ်းကျင်ပညာရှင်များအဖွဲ့သည် လုပ်ငန်းများအတွက် Generative AI ဖန်တီးမှုကို လွယ်ကူချောမွေ့စေကာ အမေးအဖြေအတွဲများကို ထုတ်လုပ်ရန်အတွက် ပြည့်စုံသောစာရွက်စာတမ်းများ သို့မဟုတ် လက်စွဲများကို စေ့စေ့စပ်စပ်လေ့လာနိုင်ပါသည်။ ဤနည်းလမ်းသည် ကျယ်ပြန့်သော ကော်ပိုရိတ်တစ်ခုမှ သက်ဆိုင်ရာ အချက်အလက်များကို တူးဖော်ခြင်းဖြင့် သုံးစွဲသူ၏ စုံစမ်းမေးမြန်းမှုများကို ထိထိရောက်ရောက် ကိုင်တွယ်ဖြေရှင်းနိုင်ပါသည်။ ကျွန်ုပ်တို့၏ အသိအမှတ်ပြုထားသော ကျွမ်းကျင်သူများသည် မတူကွဲပြားသော ခေါင်းစဉ်များနှင့် ဒိုမိန်းများကြားတွင် ပါဝင်သော အရည်အသွေးမြင့် အမေးအဖြေအတွဲများကို ထုတ်လုပ်ရန် သေချာပါသည်။

စာသားအကျဉ်းချုပ်
ကျွန်ုပ်တို့၏ ကျွမ်းကျင်ပညာရှင်များသည် ကျယ်ကျယ်ပြန့်ပြန့် စာသားဒေတာမှ တိုတိုတုတ်တုတ်နှင့် ထိုးထွင်းသိမြင်နိုင်သော အနှစ်ချုပ်များကို ပေးစွမ်းနိုင်သော ကျယ်ကျယ်ပြန့်ပြန့် စကားဝိုင်းများ သို့မဟုတ် ရှည်လျားသော ဆွေးနွေးပွဲများကို ခွဲထုတ်နိုင်စွမ်းရှိပါသည်။

စာသားမျိုးဆက်
သတင်းဆောင်းပါးများ၊ ရသစာပေနှင့် ကဗျာများကဲ့သို့ ကွဲပြားသောပုံစံများဖြင့် ကျယ်ပြန့်သောဒေတာအတွဲကို အသုံးပြု၍ မော်ဒယ်များကို လေ့ကျင့်ပါ။ ထို့နောက် အဆိုပါမော်ဒယ်များသည် သတင်းအပိုင်းအစများ၊ ဘလော့ဂ်များ သို့မဟုတ် ဆိုရှယ်မီဒီယာပို့စ်များ အပါအဝင် အကြောင်းအရာအမျိုးမျိုးကို ထုတ်လုပ်နိုင်ပြီး၊ အကြောင်းအရာဖန်တီးမှုအတွက် ကုန်ကျစရိတ်သက်သာပြီး အချိန်ကုန်သက်သာသော အဖြေကို ပေးဆောင်နိုင်ပါသည်။
မိန့်ခွန်းအသိအမှတ်ပြုမှု
အပလီကေးရှင်းအမျိုးမျိုးအတွက် စကားပြောဘာသာစကားကို နားလည်နိုင်သော မော်ဒယ်များကို တီထွင်ပါ။ ၎င်းတွင် အသံဖြင့်ဖွင့်ထားသော လက်ထောက်များ၊ သတ်ပုံဆော့ဖ်ဝဲနှင့် အချိန်နှင့်တပြေးညီ ဘာသာပြန်ကိရိယာများ ပါဝင်သည်။ လုပ်ငန်းစဉ်တွင် ၎င်းတို့၏ သက်ဆိုင်ရာ စာသားမှတ်တမ်းများနှင့် တွဲဖက်ထားသော စကားပြောဘာသာစကား၏ အသံဖမ်းယူမှုများပါရှိသော ပြည့်စုံသောဒေတာအစုံကို အသုံးပြုခြင်း ပါဝင်သည်။

ကုန်ပစ္စည်းအကြံပြုချက်များ
ထုတ်ကုန်ဝယ်လိုအားကို ညွှန်ပြသော အညွှန်းများအပါအဝင် ဝယ်ယူသူဝယ်ယူသည့်မှတ်တမ်းများ၏ ကျယ်ပြန့်သောဒေတာအတွဲများကို အသုံးပြု၍ မော်ဒယ်များကို တီထွင်ပါ။ ရည်ရွယ်ချက်မှာ ဖောက်သည်များအား တိကျသော အကြံပြုချက်များကို ပေးဆောင်ရန်ဖြစ်ပြီး အရောင်းမြှင့်တင်ရန်နှင့် သုံးစွဲသူများ စိတ်ကျေနပ်မှုကို မြှင့်တင်ရန်ဖြစ်သည်။
ပုံစာတန်းထိုး
ကျွန်ုပ်တို့၏ ခေတ်မီဆန်းသစ်သော၊ AI-မောင်းနှင်သည့် ပုံစာတန်းထိုးခြင်းဝန်ဆောင်မှုဖြင့် သင်၏ပုံရိပ်အဓိပ္ပာယ်ပြန်ဆိုခြင်းလုပ်ငန်းစဉ်ကို ပြုပြင်ပြောင်းလဲပါ။ ကျွန်ုပ်တို့သည် တိကျပြီး အဓိပ္ပာယ်ပြည့်ဝသော ဖော်ပြချက်များကို ဖန်တီးခြင်းဖြင့် ရုပ်ပုံများတွင် တက်ကြွမှုကို ထည့်သွင်းပါသည်။ ၎င်းသည် သင့်ပရိသတ်အတွက် သင့်အမြင်အာရုံဆိုင်ရာ အကြောင်းအရာများနှင့် ဆန်းသစ်သော ထိတွေ့ဆက်ဆံမှုနှင့် အပြန်အလှန်တုံ့ပြန်မှု ဖြစ်နိုင်ခြေများအတွက် လမ်းခင်းပေးပါသည်။

သင်ကြားရေး စာသားမှ စကားပြောဝန်ဆောင်မှုများ
ကျွန်ုပ်တို့သည် AI မော်ဒယ်များကို လေ့ကျင့်သင်ကြားရန်အတွက် အကောင်းဆုံးသော လူသားစကားပြောအသံသွင်းမှုများပါ၀င်သော ကျယ်ပြန့်သောဒေတာအစုံကို ပေးပါသည်။ ဤမော်ဒယ်များသည် သင့်အပလီကေးရှင်းများအတွက် သဘာဝကျပြီး ဆွဲဆောင်မှုရှိသော အသံများကို ဖန်တီးပေးနိုင်သောကြောင့် သင့်အသုံးပြုသူများအတွက် ထူးခြားပြီး နှစ်မြှုပ်ထားသော အသံအတွေ့အကြုံကို ပေးစွမ်းနိုင်ပါသည်။



